はじめに
タンパク質の翻訳は開始コドン「AUG」から始まります。また、「AUG」は開始コドンとして使われるだけでなく、タンパク質に含まれるアミノ酸の一つであるメチオニンを指定するコドンとしても使われます。つまり、一つのmRNAに「AUG」配列は複数存在するということです。ではmRNAに含まれる複数のAUGコドンの中から、細胞はどのようにして開始コドンを認識しているのでしょうか?解説していきます!
※本記事は、以下の記事で解説した翻訳機構についての知識を前提に執筆しています。難しく感じられた方は、こちらの記事からお読みください。

※以下の記事はRNAに関する基本的な解説をしています。あわせてお読みください。
【難易度】★★☆☆☆
【重要度】★★★★★
mRNA-タンパク複合体の形成
本項では最初のアミノ酸が開始コドンに運ばれる過程を見る前に、まずは翻訳開始においてとても重要であるmRNA-タンパク複合体について解説していきます。
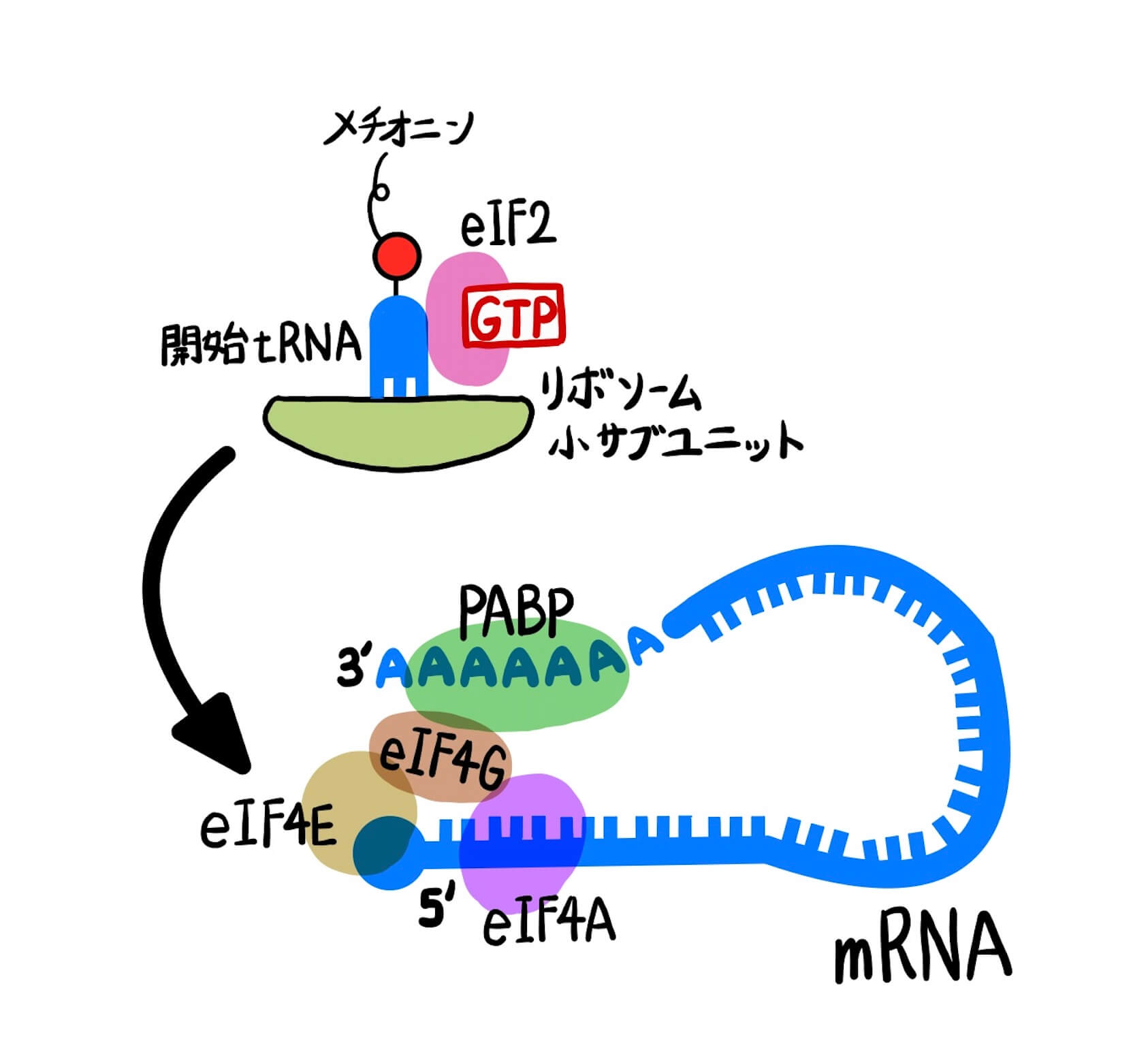
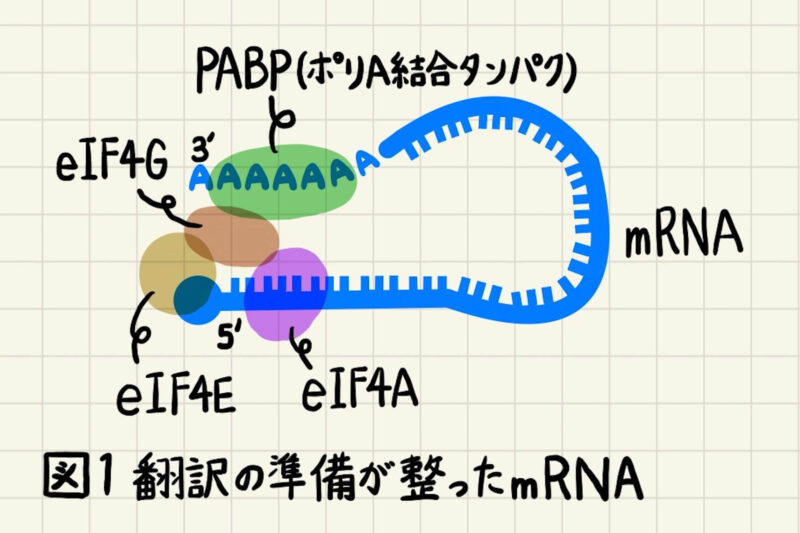
RNAスプライシングなどのRNAプロセシングが完了して翻訳の準備が整ったmRNAには、図1のようにポリA結合タンパク質(poly(A)-binding protein; PABP)、翻訳開始因子(eukaryotic initiation factor; eIF)などの複数のタンパク質が結合しています。これらのタンパク質が「RNAプロセシングが正常に完了しました。翻訳開始してください。」という目印になります。
図1中では翻訳開始に特に重要なタンパク質を図示しています。eIF4EはmRNAの5’キャップを、PABPはmRNAのポリA尾部を認識して結合し、eIF4Gを介して図1のように環状構造をとっています。このような環状構造によってRNAse(RNA分解酵素)からの分解を防いでいます。また、eIF4Aはヘリカーゼ活性をもち、RNAの高次構造をほどいてタンパク合成を行いやすくします。翻訳開始にはこのようなmRNA-タンパク複合体形成が重要であり、タンパク質の翻訳効率に大きく影響します。
RNAseは至るところに存在しており、RNAはとても分解されやすいです。実際に実験でRNAを扱う時は保存条件やRNAse-freeの試薬を使うなどの注意が必要です。
開始tRNAとリゾソーム小サブユニットが翻訳を開始する
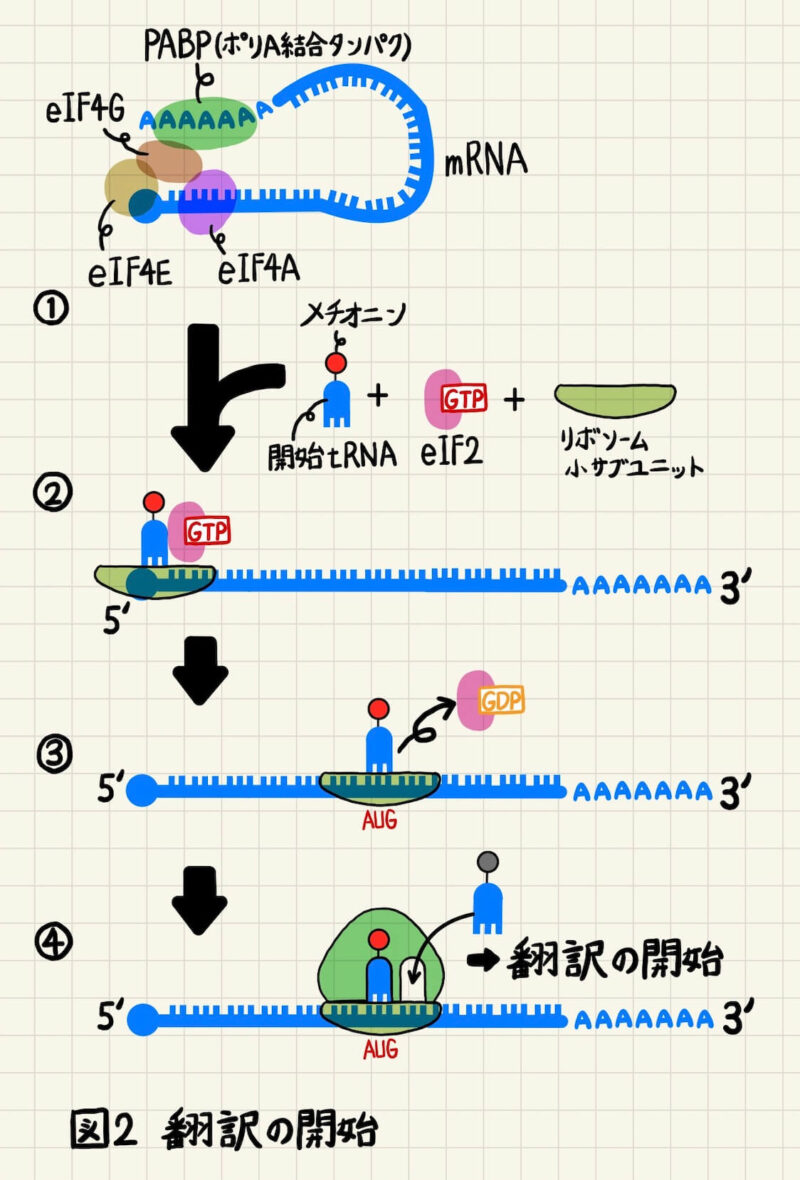
開始コドンにメチオニンを運搬するtRNAを開始tRNAと言います。通常のメチオニンを運搬するtRNAとは異なるので、開始tRNAという名前がついています。
翻訳の開始ではまず開始tRNAにeIF2が結合し、eIF2が開始tRNAをリボソームの小サブユニットのP部位へと運びます(図2①)。メチオニン-開始tRNA、eIF2、リボソームの小サブユニットの複合体は、mRNAの5’キャップ構造に結合し、mRNAの5’から3’方向に向かって移動しながらAUGを探していきます(図2②)。複合体がAUGに出会うと、eIF2が結合していたGTPがGDPへと加水分解され、開始tRNAから解離します(図2③)。するとリボソームの大サブユニットが結合してリボソームが完成します。その後はA部位に新しく付加されるアミノアシルtRNAが到着し、通常の伸長サイクルに入ります(図2④)。
AUGはメチオニンをコードしているので、タンパク質の合成は必ずメチオニンから始まります。 ではタンパク質のN末端はすべてメチオニンなのかと言われるとそうではなく、ほとんどの場合N末端の最初のメチオニンは取り除かれます。
原核生物の翻訳開始機構
原核生物のmRNAは5’キャップ構造がなく、上述のような翻訳開始機構はありません。その代わりに原核生物の開始コドンの数塩基上流にはシャイン・ダルガーノ配列(Shine‐Dalgarno sequence; SD配列)と呼ばれる塩基配列があります。原核生物のリボソームは、このシャイン・ダルガーノ配列を認識してその数塩基下流にあるAUGからタンパク合成を開始します。
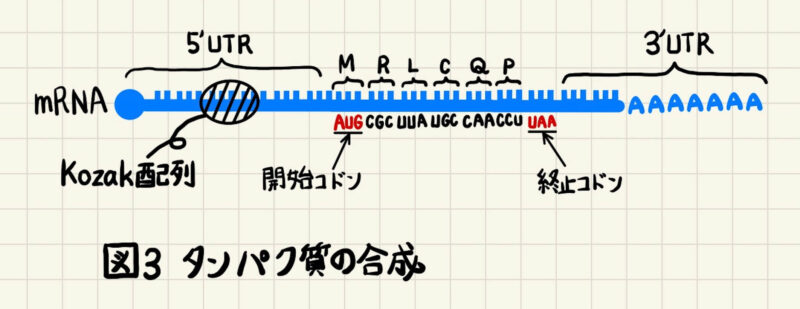
SD配列と類似した配列は真核生物にも存在しており、コザック配列(Kozak配列)と呼ばれています(図3)。ただし、真核生物のKozak配列は多様性があり、その詳細な機能はわかっていませんが、効率的な翻訳のために重要な配列であることには変わりありません。
読み枠は1塩基ずれるだけで全く異なるタンパク質ができてしまうので、このように翻訳の開始点は非常に厳密に決められています。
開始コドンは読み飛ばされることがある
開始tRNA-リボソーム小サブユニット複合体はmRNAの5’キャップからAUGを探していきますが、最初に出会った開始コドンを読み飛ばしてしまうことがあります。すなわち、2番目や3番目に出会った開始コドンからタンパク質を合成することがあります。アミノ酸の5’末端には、タンパク質の局在を示すシグナル配列が含まれていることが多く、この開始コドンのスキップは局在の異なるタンパク質を作る上で重要です。
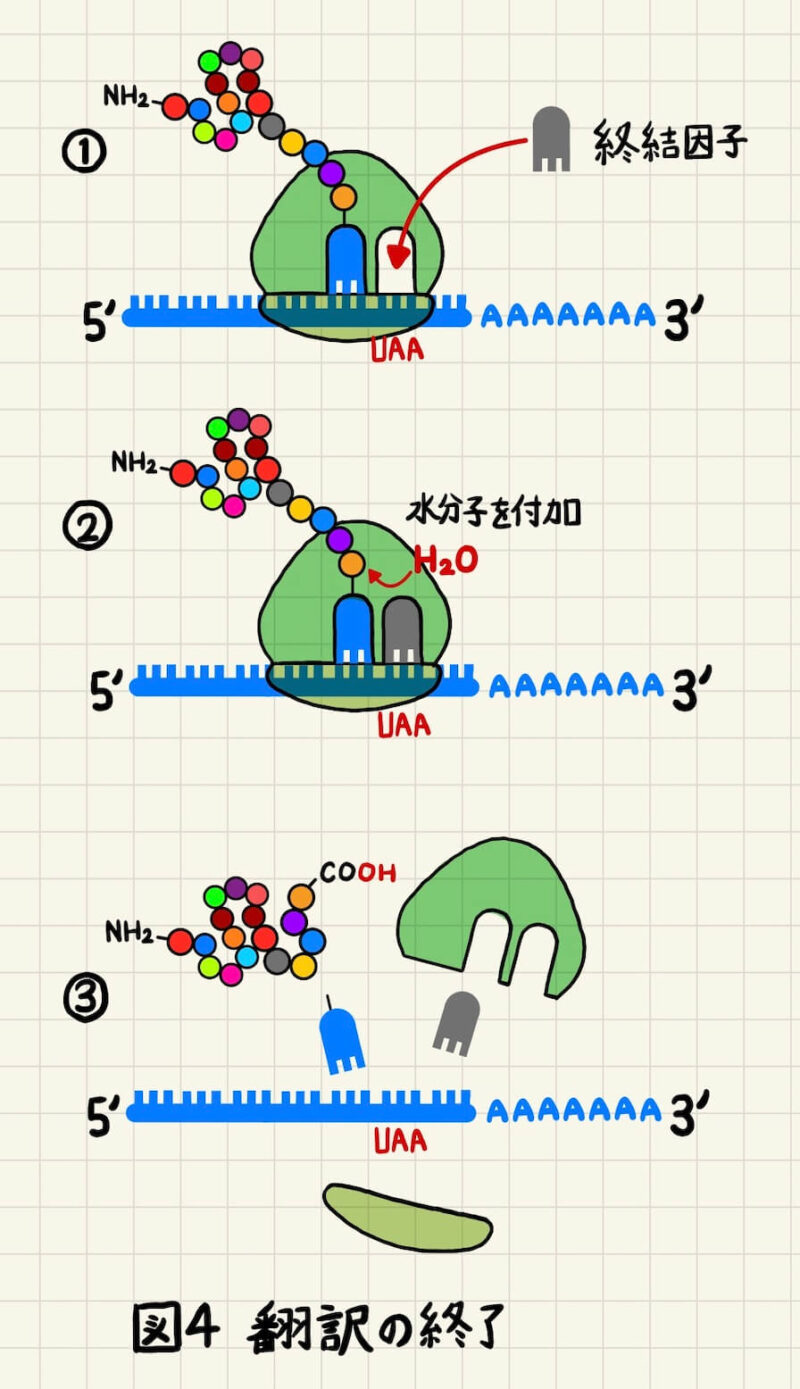
翻訳の終了
リボソームのA部位に終始コドン(UAA、UAG、UGA)がくると、アミノアシルtRNAの代わりに終結因子(release factor)が結合します(図4①)。終結因子がA部位に都合すると、リボソームはアミノ酸の代わりに水分子をポリペプチド鎖に付加し、タンパク質はリボソームから解離します(図4②)。それに伴い、リボソームも2つのサブユニットに解離し、次のmRNAの翻訳に使われます(図4③)。
まとめ
- 翻訳の準備が整ったmRNAには、ポリA結合タンパク質や翻訳開始因子などが結合し、環状構造をとる。
- リボソーム小サブユニットとtRNAの複合体はmRNAの5’末端に結合し、3’末端に移動しながら開始コドンAUGを探す。
- タンパク質の合成は必ずメチオニンから始まるが、ほとんどの場合タンパク質のN末端のメチオニンは取り除かれる。
- 原核生物の翻訳開始ではシャイン・ダルガーノ配列が重要。真核生物にも類似する配列があるが(コザック配列)、その配列に当てはまらないものも多い。
- 開始コドンは読み飛ばされることがあり、N末端の異なるタンパク質が作られる。
- リボソームのA部位に終始コドン(UAA、UAG、UGA)がくると、終結因子(release factor)が結合し、翻訳を終了させる。